di Francesca Melas (testo) e Cinzia Melis (grafica)
In questo terzo seminario tematico di L.U.Di.Ca 2021 la professoressa Deborah Paci, dell’Università Ca’ Foscari di Venezia, ci ha mostrato l’importanza del text mining – il processo automatizzato di estrazione dell’informazione (significativa e rilevante) da un file di testo – e delle sue applicazioni all’interno della digital history.
Dopo aver esplorato gli strumenti di cui il text mining si serve (machine learning), la prof.ssa Paci ci ha fornito una panoramica delle metodologie di pre-processing, che nel risolvere le ambiguità del testo presentano, però, alcuni limiti di automazione, che abbiamo in seguito analizzato.
Ci siamo poi soffermati su Voyant, software open-source per l’analisi testuale realizzato nel 2003 da Stéfan Sinclair & Geoffrey Rockwell. Questo applicativo è ottimizzato per la processazione di testi brevi, abbiamo quindi esplorato le sue funzionalità utilizzando come esempio il testo di alcuni discorsi pubblici.
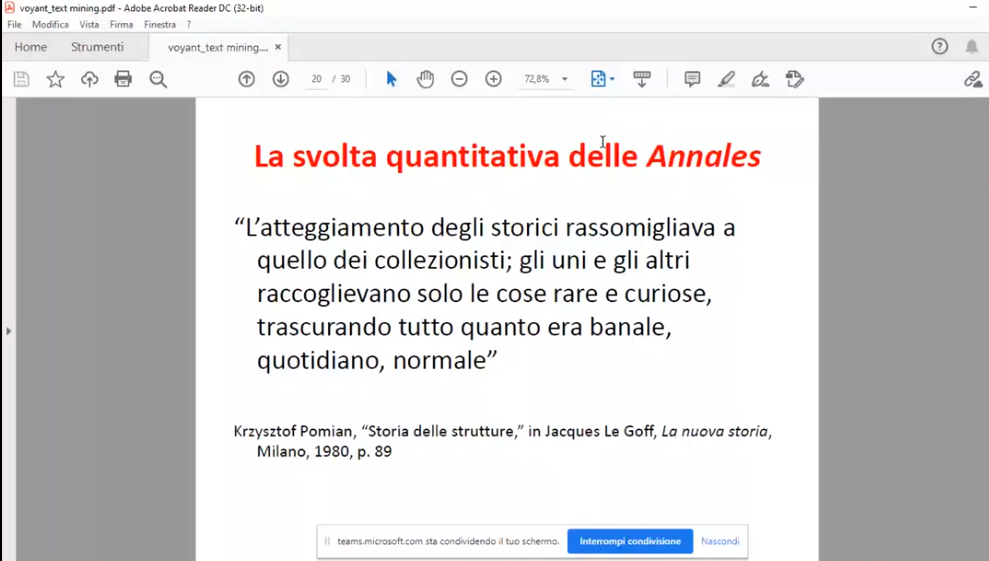
Il programma esplica il suo potenziale nell’analisi quantitativa dei dati tipica del distant reading, approccio elaborato da Franco Moretti in opposizione al più tradizionale close reading, di matrice ermeneutica-interpretativa, che analizza invece il significato del testo in rapporto al contesto che l’ha generato.
Si pone perciò un quesito fondamentale e divisivo nelle scienze storiche: può esistere un punto di incontro tra metodologie tra loro così distanti?
Abbiamo rilevato insieme come il software analizzato oggi sia maggiormente efficace se concepito come strumento non esclusivo ma di supporto nell’attività di ricerca dell’umanista digitale, per il quale si rende indispensabile lo sforzo di conoscere e comprendere le diverse metodologie, in modo da poter scegliere consapevolmente e puntualmente gli strumenti di cui servirsi.